
20.2 Architecture
Figure 20.1 shows the various components of a running Perl system. Shaded rectangles represent data structures, some of which can have multiple instances in a program. The source code can also be partitioned roughly along these lines.
Figure 20.1: Snapshot of a running system
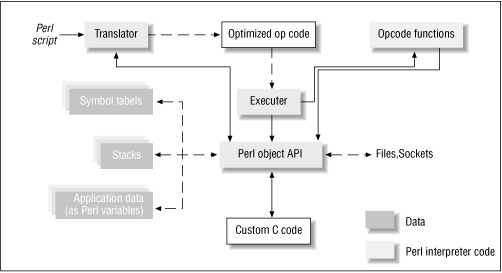
20.2.1 Perl Objects
The box "Perl object API" in Figure 20.1 represents the API to manipulate all internal data structures, such as variables, symbol tables, stacks, and resources such as files and sockets.
- Variables
We saw in Chapter 3, Typeglobs and Symbol Tables, that the term "variable" refers to a name-value pair. In this chapter, we will look at the API to manipulate the different types of values and to optionally bind them to names. A value can be one of the following:
SV: Scalar value AV: Array value HV: Hash value CV: Code value GV: Glob value (or typeglob) RV: Reference value An SV can further be classified as an IV (integer value), PV (string value), or NV (double). The abbreviations are part of a uniform naming convention, so you can easily guess the intent of a function named newSViv, for example.
These value types provide a simple API, resize themselves automatically, and follow simple memory management protocols. For this reason, most Perl internal data structures such as stacks and symbol tables are also implemented in terms of these values.
- Symbol tables
Symbol tables are plain old HVs, whose keys are identifier names (strings) and whose values are pointers to GVs. But aren't values in a hash table supposed to be scalars? The answer coming up, in the section "Glob Values and Symbol Tables."
- Stacks
As Perl executes a script, it keeps run-time information in several stacks, the most important one being the "argument stack," or stack as it is simply known in the Perl source. The idea is simple: if foo wants to call bar with two arguments, it pushes these two scalars on the top of stack and calls bar. bar picks up these scalars, does its stuff, and dumps the results back on the stack. The stack is a simple AV, and every nested call occupies a stretch of the stack with its own parameters.
C programmers think of a stack as containing subroutine parameters, temporaries, and auto variables (those local to that scope). The Perl interpreter implements a different model. The stack described above holds only subroutine parameters; there are other stacks to track temporary variables generated during computations, local variables, and other miscellaneous tidbits of information such as loop iterators, the next opcode to execute on encountering last, redo, or return, and so on. The section "Stacks and Messaging Protocol" has more details.
- I/O abstraction
Perl internally uses an object called PerlIO for all its I/O needs. This abstraction is essentially a thin porting layer for two libraries: stdio, and the much faster alternative, sfio [6]. We will not cover the I/O abstraction in this chapter, primarily because it is simple and offers no great insights. Please read the perlapio document for details.
20.2.1.1 Multiple interpreters
The data structures described above are normally kept in global C variables. If Perl is compiled with -DMULTIPLICITY, it lumps all these global variables into a structure called PerlInterpreter. This allows you to have multiple instances of the interpreter, each with its own "global" space. (Recall from Chapter 19, Embedding Perl:The Easy Way the API to allocate and construct an object of type PerlInterpreter.) In the absence of this compile-time option, the PerlInterpreter object is a dummy structure, and the internal data structures are truly global, for maximum performance. The API remains the same in either case.
You can use multiple interpreters to enforce completely isolated namespaces. Each interpreter has its own "main" package and its own tree of loaded packages. I have not seen this feature used in production Perl applications, but Tcl provides a framework called SafeTcl for security purposes, which uses a similar feature of multiple interpreter objects. These interpreters can be unrestricted or restricted. The equivalent module in Perl, Safe, uses a different mechanism, though the result (of isolated name spaces) is similar. More on this in the next section.
20.2.2 Translator
The translator converts a Perl script into a tree of opcodes (explained below). It comprises a hand-coded lexer (toke.c), the yacc-based parser (perly.y), and the code generator (op.c). Regular expressions - which form a distinct sublanguage - are recognized in toke.c and compiled to an internal format in regcomp.c.
Opcodes are similar in concept to machine code; while machine code is executed by hardware, opcodes (sometimes called byte-codes or p-code) are executed by a "virtual machine." The similarity ends there. Modern interpreters never emulate the workings of a hardware CPU, for performance reasons. Instead, they create complex structures primed for execution, such that each opcode directly contains a pointer to the next one to execute and a pointer to the data it is expected to work on at run-time. In other words, these opcodes are not mere instruction types; they actually embody the exact unit of work expected at that point in that program.
Java and Perl are both examples of such interpreters. While many of Java's bytecodes resemble a RISC machine's instruction set, Perl's opcodes represent a much higher level of abstraction. A large number of these opcodes directly correspond to the facilities available at the scripting level, such as regular expression matching and substitution, chop, push, index, rindex, grep,[3] and so on, which explains why there are 343 opcodes as of this writing! It also explains why Perl is so fast: instead of spending time in the interpreter, most of the work is done in lovingly hand-optimized C code. You can also see why it is hard to create a Perl-to-Java byte-code translator: there is no correspondence between the two sets.
[3] Perl's
grepoperator, not the Unix utility. It hasn't come to a point at which entire utilities are represented by opcodes!
20.2.2.1 Inside opcodes[4]
[4] Unless you want a gut feeling for what goes on deep inside, you don't have to digest - or even read - this section on a first pass over this chapter. Sections entitled "Inside..." are meant to be reasonably standalone pieces.
op.h defines a basic structure called op, shared by all opcodes. The important fields, discussed in this section, are:
OP* op_next; OP* op_sibling; OP* (*op_ppaddr)(); OPCODE op_type;
The op_type field contains the actual type of the opcode. A listing of all opcode types is present in opcode.h, produced automatically by the script opcode.pl while building the interpreter. The script contains a nicely tabulated description of all opcodes and hence is a much better source of information than opcode.h.
The op_ppaddr pointer represents the essence of the opcode: it is a pointer to a built-in function - call it an opcode function - that implements the functionality of the opcode. All opcode functions are prefixed with pp (pp_push, pp_grep, and so on) and are distributed over pp.c, pp_ctl.c, pp_sys.c, and pp_hot.c. The last one contains the opcode functions that are "hot," or frequently executed, so it is likely to remain within the cache of most RISC systems. Tom Christiansen once mentioned that this feature is also true of the regular expression-matching code, which is why regex matchers written in Java won't come anywhere close in performance. (I'll reevaluate this claim once Sun's Java processors are freely available.) As you will see later on, the opcode functions look strikingly similar to the glue code output by xsubpp/SWIG ; this is because they interoperate using the argument stack and obey the same parameter passing protocols.
Opcodes have additional structure members depending on their type. For example, the add opcode is a binary operator, and hence contains two pointers to its children, which it evaluates before adding up the results. The print opcode is a list operator, and hence contains a pointer to the first opcode in its list of children, which are then linked to their siblings using the op_sibling pointer (possessed by all opcodes), and so on.
This complex interlinked mesh of opcodes is referred to as a syntax tree. Figure 20.2 shows such a tree, a result of parsing the expression print $a + 2.
Figure 20.2: Syntax tree and thread of execution for "print $a + 2"
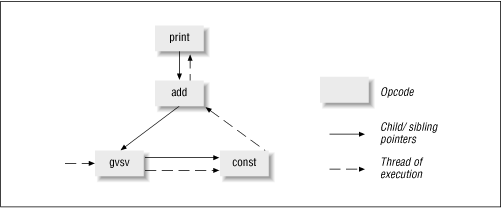
The syntax tree's top-down hierarchy indicates the precedence of expressions; the subexpression $a + 2 must be computed before printing can commence. By the same token (pun unintended), $a's value and the constant 2 must be retrieved and placed on the stack before addition can happen. The gvsv opcode (which fetches $a's value) and the const opcode are thus children of the add opcode, and have a sibling relationship to each other. The add opcode is in turn a child of the print opcode. As you can see, the network of child and sibling pointers reflect the syntactic structure of the program.
The op_next pointer points to the next opcode to be executed and hence reflects the flow of control. Executing the code is thus a simple matter of moving to the next opcode and calling its opcode function. The dashed lines in Figure 20.2 indicate this thread of execution.
If you compile Perl with -DDEBUGGING, you can use the -Dx command-line option to tell it to dump its syntax tree after it finishes parsing a script. The output of an example invocation, perl -Dx -e 'print $a + 2', is shown in Example 20.1. The nesting level reflects the hierarchy - Figure 20.2 turned on its side - and the numbering scheme shows the order of execution. (I've added the comments on the right; the rest of the output is Perl's.)
Example 20.1: Opcode Sequence and Hierarchy for "print $a + 2"; Using -Dx
{
8 TYPE = leave ===> DONE # Clean up. The last instruction
FLAGS = (SCALAR,KIDS,PARENS)
{
1 TYPE = enter ===> 2 # Enter here
}
{
2 TYPE = nextstate ===> 3 # nextstate inserted after every
# statement to clean up temporaries
FLAGS = (SCALAR)
LINE = 1
}
{
7 TYPE = print ===> 8 # call print. Contains child
# expressions to be evaluated first
FLAGS = (SCALAR,KIDS)
{
3 TYPE = pushmark ===> 4
FLAGS = (SCALAR)
}
{
6 TYPE = add ===> 7 # add requires two arguments
TARG = 1 # to be available on top of the
FLAGS = (SCALAR,KIDS) # argument stack (discussed below)
{
TYPE = null ===> (5)
(was rv2sv)
FLAGS = (SCALAR,KIDS)
{
4 TYPE = gvsv ===> 5 # Get the scalar value associated
FLAGS = (SCALAR) # with the name "main::a"
GV = main::a
}
}
{
5 TYPE = const ===> 6 # Put the constant "2" on the stack
FLAGS = (SCALAR)
SV = IV(2)
}
}
}
}Each pair of braces represents information about a specific opcode. The first opcode to execute is enter. It then hands control over to nextstate, which in turn leaves it to pushmark, and so on. The nextstate opcode cleans up all temporaries introduced in a statement and prepares for the next statement in that scope. The intent of the pushmark opcode will be clear when we study the parameter-passing protocol later in this chapter.
At compile time, the gvsv opcode (which fetches global or local variables) is primed with the address of the value it intends to fetch and place on the stack when it is executed. This means that at run-time, it does not have to refer to the symbol table at all - it already possesses the value. The symbol table is consulted only when you use features such as symbolic references, dynamic binding of functions, and eval, which do not have all the information at compile-time.
20.2.2.2 Compilation and code generation stages
yacc works in a bottom-up fashion, so the opcodes at the leaf-level of the syntax tree are produced first. As parsing proceeds, opcodes at a higher level in the syntax tree thread together the nodes below. Each unary and binary opcode (an arithmetic operator, for example) is checked to see whether it can be immediately executed; this is called constant folding. If it can, that opcode and its children are removed, and a new const opcode is substituted in place. Next, opcodes corresponding to built-in functions are verified to see that they have the right number and type of parameters.
Then comes context propagation. On creation, each opcode gets to specify a context (void, Boolean, list, scalar, or lvalue) for itself and its child opcodes. Consider the expression substr(foo(), 0, 1). The opcodes representing a call to foo and the constants 0 and 1 are created first. When the opcode for substr is subsequently created, it tells the opcode representing the call to foo that it wants a scalar as its result. Context propagation hence works top-down.
When parsing is complete, a peephole optimizer goes to work (function peep in op.c). It traces all branches of execution, following the op_next pointers just as it would during run-time, and scouts for local optimizations. (That is, it does a dry run of the execution path.) The procedure typically examines the next few opcodes in sequence (currently, at most two) and checks to see whether they can be reduced to simpler or lesser opcodes; it looks through a peephole, in other words. Let us investigate this a little with a small example.
A `$' can be followed by an identifier name ($a), an array element ($l[0]), or, in the most general case, an expression resulting in a scalar reference ($$ra or ${foo()}. In the first pass, the parser assumes the most general approach, so even something as simple as $a boils down to two opcodes: gv and rv2sv. The first one retrieves a GV (a typeglob, which, if you think about it, is a reference to a scalar value) and places it on the stack, and the second opcode converts this to an SV. Along comes the peephole optimizer and replaces this sequence to one opcode, gvsv, which can do the same thing in one shot. The problem is that deleting unwanted opcodes is time-consuming and tedious, since these opcodes contain links to other opcodes. For this reason, useless opcodes are simply marked as null, and the op_next pointer of the previous opcodes simply bypasses them (the nullified opcodes). Example 20.1 shows an example of a nullified opcode; look for the line TYPE = NULL (was rv2sv).
20.2.2.3 Security features
Perl provides the -T switch to enable taint checking, which marks all variables containing data derived from outside the program as tainted. It implements a data flow mechanism, whereby all variables derived from these variables are also considered tainted. (Pushing a tainted scalar into an array marks the array as suspicious.) Essentially, this means you trust the code to do the right thing and to discriminate between tainted and untainted data. But if the code itself is suspicious, you can use the standard module Safe and its companion package Opcode.[5] These modules allow you to create a safe compartment and specify an operator mask (a list of allowed opcodes) for that compartment. You can eval a piece of untrusted code inside this compartment, and if the compilation process produces an opcode that is not present in the opcode mask, it returns an error. In the next few versions, Perl is expected to account for other kinds of malicious attacks, such as unlimited allocation of memory (@l = (1..1000000)) or CPU starvation (1 while (1)). These are also known as denial of resource attacks.
[5] Both designed by Malcolm Beattie (check the ext/Opcode subdirectory in the standard Perl library).
20.2.3 Executor
The executor (function runops in run.c) is a simple driver that traverses the execution chain in the syntax tree and calls each corresponding opcode function in sequence. But because Perl is such a dynamic language, the path of execution cannot always be determined at the outset, so every opcode function is expected to return the next opcode to execute. For the most part, it is the next opcode in sequence (the op_next pointer set during compile time). But some, such as conditional operators like if or indirect expressions like $foo->func(), can determine the next opcode to execute only at run-time.
 |  |  |
| 20.1 Reading the Source |  | 20.3 Perl Value Types |